
Navigating Customer Support through AI in the context of B2B SaaS - The role of Embedding Models and LLMs.
As technology evolves, so do the tools and methodologies for enhancing various functions. In this piece, we will explore GenAI applications in three orchestration scenarios for customer support.


In the dynamic world of B2B enterprise platforms, with a global customer base across web and mobile ecosystems, the role of customer support teams is crucial. As technology evolves, so do the tools and methodologies for enhancing customer support efficiency. In this piece, we will explore GenAI applications in three orchestration scenarios:
Scenarios leveraging only embedding models for tasks like categorization and automated triage.
Scenarios solely dependent on Large Language Models (LLMs) for generating personalized responses and real-time language translation.
Scenarios combining both, offering advanced sentiment analysis and streamlined resolution processes.
We will start by delving into what embedding models are, their unique strengths, and how they are employed in these scenarios.
Embedding models fall under the discipline of machine learning in artificial intelligence (AI), specifically within the realm of representation learning. This branch of AI focuses on methods that allow a system to automatically discover the representations needed for feature detection or classification from raw data. In the case of embedding models, the goal is to transform complex, high-dimensional data into a lower-dimensional space while preserving relevant properties of the original data, making them highly suitable for tasks in natural language processing, computer vision, and other areas requiring efficient data representation.
To provide an analogy for embedding models, imagine you have a recipe box full of different recipes. An embedding model is like a magical tool that helps you organize these recipes in a very smart way. It reads each recipe and understands what it's about, then arranges them so that similar recipes are grouped together. For example, all the cake recipes would be in one spot, and all the soup recipes in another. This makes it much easier to find what you're looking for, just like how this tool helps computers organize and understand complex information.
Real-World Use Case: Supermarket Layout Optimization
Imagine a large supermarket chain that wants to optimize the layout of its stores. An embedding model can be used to understand shopping patterns and group similar products. By analyzing purchase data, the model identifies which products are frequently bought together. For example, it might find that people who buy pasta also often buy tomato sauce and Parmesan cheese. The supermarket can then arrange these items close to each other, making shopping more convenient for customers and potentially increasing sales.
Digital Use Case: Personalized Movie Recommendations
A streaming service wants to provide personalized movie recommendations to its users. An embedding model is used to understand users' viewing habits and the characteristics of various movies. Each movie and user is represented as a vector in a digital space. The model learns from past viewing patterns, clustering similar movies and aligning users with movies they're likely to enjoy. For instance, if a user frequently watches romantic comedies, the model will recommend movies from this genre, enhancing user experience and engagement with the service.
Advantages of Embedding models
Embedding models bring distinct strengths to the forefront of AI, especially in natural language processing. They excel in contextual understanding, interpreting words and phrases within their surrounding context, rather than just as standalone entities. This advancement significantly surpasses the capabilities of traditional keyword-based approaches. Moreover, embedding models efficiently handle high-dimensional data, simplifying complex information while retaining crucial aspects, which enhances computational efficiency. They also offer improved methods for measuring similarity between texts, playing a pivotal role in search engines, recommendation systems, and content classification. Versatile in nature, these models are not limited to textual data; their application spans across various forms, including visual and auditory data, making them invaluable tools in a wide range of AI applications. These strengths demonstrate a marked evolution from previous methodologies, opening new avenues in the realm of artificial intelligence.
Scenario 1: Scenarios leveraging only embedding models: Automated ticket triage.
In this scenario, lets take the example of a support engineer who is tasked with triaging a support case and identifying duplicates. When a new support case arises, such as a complaint about the application being slow on performance for a user, the engineer must quickly determine whether it's a known issue or a new one. This is achieved using an embedding model to create a vector representation of the issue. The engineer then searches the database with a specific SQL query to find the nearest neighbor, focusing on open bugs. This approach utilizes the current operational system and its data to identify the most relevant existing bugs. The results allow the engineer to determine if the issue is already known, potentially annotating it for future reference, or if a new case needs to be created.
This method exemplifies the use of similarity search integrated with the latest data, showcasing the growing significance of embeddings in both unstructured and structured data within the database industry. Embeddings are becoming a key tool, predicted to transform database management and entity relationship modeling.
Let’s decompose this. When a support engineer uses an embedding model to handle a new support case, it works like this: The engineer inputs the details of the case into the system. This could be a description of a technical issue or a customer's query. The embedding model then processes this information and converts it into a vector, which is essentially a set of numbers that represents the key features of the case in a way the computer can understand. This numerical representation is like a unique fingerprint of the case.
Next, the system compares this fingerprint with the fingerprints of existing known issues (open bugs) stored in its database. It does this using a method called 'nearest neighbor search', which essentially looks for the most similar fingerprints (or cases). If a very similar or identical fingerprint is found, it indicates that this issue has occurred before and is already known. If not, it suggests that the issue is new and needs a different approach to resolve. This process helps the engineer quickly identify whether they are dealing with a recurring issue or something new, allowing for more efficient and accurate support.

To illustrate the process described in the statement using code, let's break it down into two main parts: generating a vector representation with an embedding model and searching the database for the nearest neighbor.
Generating Vector Representation with an Embedding Model:
from some_embedding_model_library import EmbeddingModelmodel = EmbeddingModel() # Initialize the embedding modelissue_description = "Application is slow to load" # Example issue descriptionissue_vector = model.generate_vector(issue_description) # Generate vectorIn this example code snippet uisng Python, an embedding model is used to convert the textual description of the issue into a vector representation. The model could be from a machine learning library and is trained to understand and convert text into numerical vectors.
Searching the Database for the Nearest Neighbor:
SELECT bug_id, similarity_score FROM bugs WHERE status = 'open' ORDER BY calculate_similarity(issue_vector, bug_vector) DESC LIMIT 5;This SQL query would be used to find the closest matches to the issue vector among open bugs in the database. The function calculate_similarity computes the similarity between the issue vector and the vectors of existing bugs (represented here as bug_vector). The query returns the top matches based on this similarity score.
In practice, the exact implementation details depend on the specific technologies and frameworks used. The code for the embedding model would depend on the machine learning library (like TensorFlow, PyTorch), and the database querying might involve specific functions for similarity calculations based on the database system in use.
Scenario 2: Scenarios solely dependent on Large Language Models (LLMs) for generating personalized responses and real-time language translation: Automated Email Generation.
In this scenario, we're focusing on using large language models (LLMs) to assist a support engineer in generating an email to a customer. The process begins with a pre-defined instruction set, or a prompt, developed by a programmer or engineer. This prompt acts as a template, requiring details like the incident description, timeline, and affected resources. To gather this information, a SQL query is executed on the operational database. With the fetched data, the prompt is augmented, creating a detailed guideline for the LLM. The LLM then generates an email, which articulates the user-facing impact and necessary details, while omitting internal technical jargon. The process encompasses three primary steps: data retrieval from the database, prompt augmentation with the retrieved data, and finally, the generation of the email by the LLM. This approach reflects a familiar pattern in the industry, drawing parallels to past practices of building database-backed web applications, but now integrating LLMs. The concept isn't entirely new but is an evolution, blending traditional database management with advanced language models in modern applications.
Roles and steps involved in automated email generation using a Large Language Model:
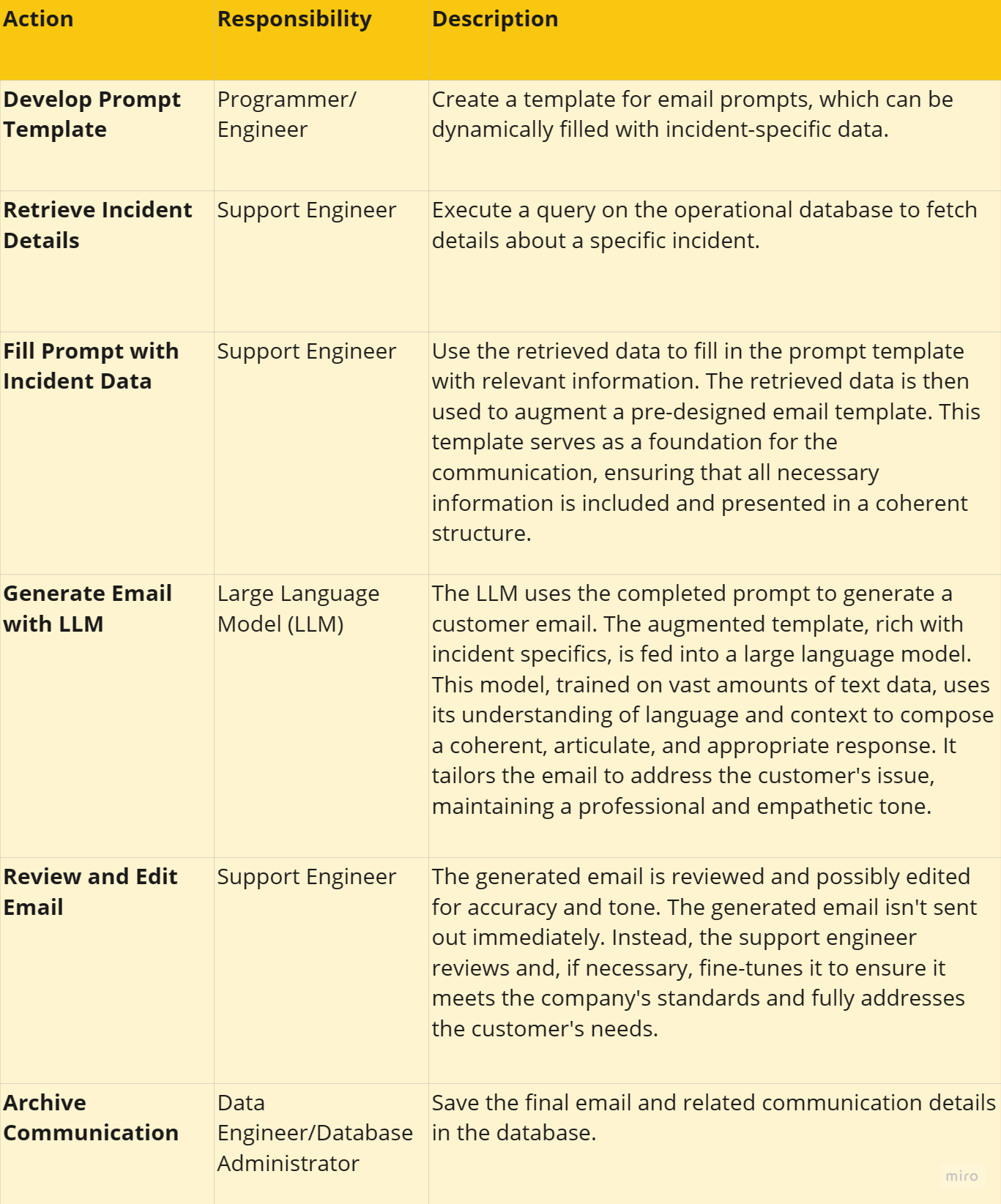
To illustrate how this could be programmatically achieved:
Prompt Template Development:
prompt_template = "Write an email regarding Incident ID: {incident_id}, describing the issue: {description}, impacted resources: {resources}, start and end time: {start_time} to {end_time}, and user-facing impacts: {user_impact}."The programmer/engineer creates a template with placeholders for incident-specific information using Python.
Retrieving Incident Details:
SELECT description, resources, start_time, end_time, user_impact FROM incidents WHERE incident_id = '12345';The data team runs a SQL query to gather detailed information about the incident.
Filling the Prompt:
# Assuming we have the incident details as variables filled_prompt = prompt_template.format(incident_id="12345", description=description, resources=resources, start_time=start_time, end_time=end_time, user impact=user_impact)The support engineer fills the prompt template with the actual data of the incident.
Email Generation with LLM:
The LLM takes the filled prompt and generates an email. This part is more abstract as it involves interacting with an LLM API or service, and the specific code will depend on the LLM being used.
Review and Edit Email:
This is a manual process where the support engineer reviews the generated email for any necessary edits.
Archiving Communication:
INSERT INTO email_archive (incident_id, email_content) VALUES ('12345', 'Generated email content');The final email and its details are archived in the database by the data team.
Scenario 3: Scenarios combining both, offering advanced sentiment analysis and streamlined resolution processes: Real-Time Chat Response.
In our exploration of advanced customer support scenarios, we delve into the fusion of embedding models and Large Language Models (LLMs). This innovative approach leverages historical chat data and current incident reports to provide contextually rich, real-time chat responses. Here's a breakdown of the process:
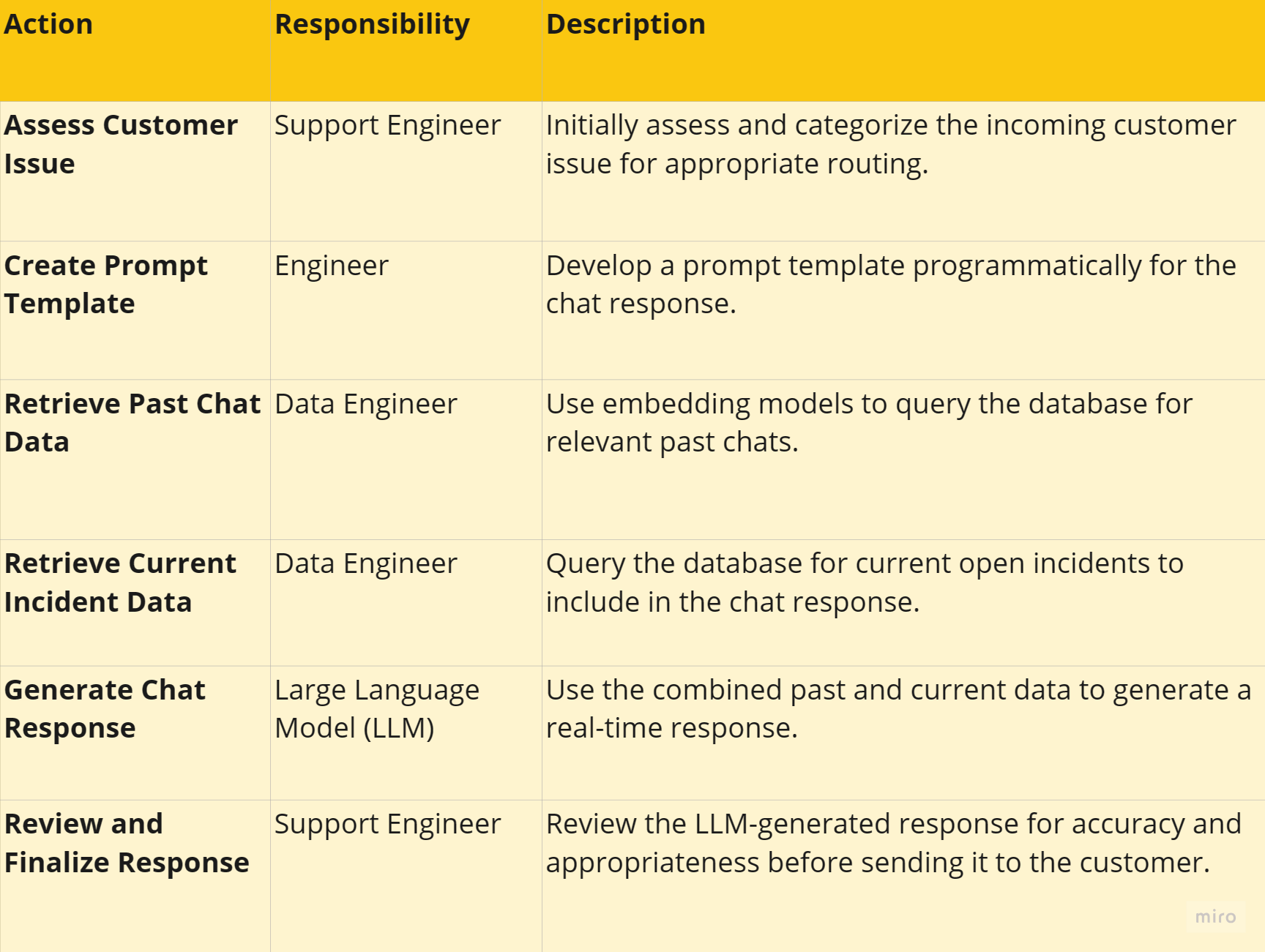
This method epitomizes the concept of 'long-term memory for large language models', emphasizing the efficient use of relevant and concise information. Moreover, it signifies a shift towards database-driven AI orchestration, allowing LLMs to interact seamlessly with external databases and APIs. This sophisticated approach not only enhances the accuracy of support responses but also paves the way for more integrated AI applications in customer service.
To illustrate how this could be programmatically achieved:
Create Prompt Template:
prompt_template = "Respond to {customer_id} about {current_issue}, referencing past issues {past_issues}."
Form a template to guide the response, incorporating customer ID, the current issue, and past related issues.
Retrieve Past Chat Data (Pseudocode for Vector Query):
past_chats = embedding_model.query("SELECT * FROM chats WHERE customer_id = {} AND date > {}", customer_id, last_month)
Query past chat interactions for the same customer, focusing on recent ones.
Retrieve Current Incident Data (SQL Query):
SELECT * FROM incidents WHERE status = 'open'
Fetch data on open incidents that might be relevant to the customer's current query.
Generate Chat Response (Pseudocode):
response = LLM.generate(prompt_template.format(customer_id=12345, current_issue=current_issue, past_issues=past_chats))
Combine the gathered data to generate a contextually relevant and accurate chat response.
This combination of steps and corresponding code snippets provides a comprehensive overview of using embedding models and LLMs in real-time chat response scenarios.
In conclusion, embedding models and Large Language Models (LLMs) are revolutionizing customer support in B2B SaaS environments. By leveraging these AI technologies, businesses can significantly enhance the efficiency and effectiveness of their customer interactions. Whether through precise categorization, personalized communication, or advanced issue resolution, these tools offer a new frontier in understanding and responding to customer needs. As these technologies continue to evolve, they promise to further transform the landscape of customer support, making it more responsive, accurate, and customer-centric.
Disclaimer: The views and insights expressed in this article are based on information gathered from various public sources on the internet and do not reflect any proprietary information belonging to the company where the author is currently employed or has worked in the past. The content is purely informative, intended for educational purposes, and not linked to any confidential or sensitive company data.
This article was inspired by a compelling segment from the talk "The Future of Databases with Generative AI" at the Google Tech Cloud event. The insights from this discussion profoundly influenced the concepts and viewpoints explored in this piece.