
Beyond the Cloud: Harnessing the Power of Edge AI for Industry-Specific Solutions
How Lightweight Models and Contextual Intelligence Could Transform Domain-Specific Applications with Real-Time Edge AI


Large Language Models (LLMs) are fundamentally changing the way industries utilize, interpret, and apply data-driven insights. Sectors like agriculture, finance, healthcare, and energy are no longer relying on generic, one-size-fits-all AI solutions. Instead, they are pivoting towards more tailored approaches that directly address the unique challenges and requirements of each industry. By employing techniques like Fine-Tuning and Retrieval-Augmented Generation (RAG), these models are evolving beyond their original broad applications, enabling them to provide detailed, context-specific recommendations and insights that are essential for informed decision-making.
This approach not only enhances the model’s understanding of domain-specific terminology and processes, but also allows it to incorporate real-time, dynamic information from external sources, making the output more relevant and actionable. Furthermore, the development of newer lightweight models, such as Mistral’s Ministral family, marks a pivotal step towards making these AI capabilities accessible on edge devices. These advancements pave the way for more focused, adaptable, and resource-efficient AI solutions that can operate effectively in environments where low latency, privacy, and localized processing are crucial. This guide takes a closer look at these transformative techniques and explores how they can open new opportunities for specialized applications across various industries.
From Generalist to Specialist: Fine-Tuning LLMs for Industry-Specific Expertise
When thinking about how LLMs operate, it's clear they come with a broad foundation of knowledge—a general understanding that can answer many types of questions with reasonable accuracy. However, real-world applications in industries like agriculture, finance, or healthcare often require more than just general insights. They demand a deeper, context-specific understanding of specialized terms, processes, and scenarios that are unique to each field. This is where fine-tuning steps in to bridge that gap.
Fine-tuning takes an existing pre-trained model, which has already been trained on a wide variety of data, and refines it using datasets tailored specifically to a particular industry. By focusing on data relevant to the domain—such as crop management practices, weather patterns, or pest control techniques in the case of agriculture—the model becomes equipped to handle specialized queries. Take, for example, the case demonstrated by Microsoft’s research, where fine-tuning was applied to an agricultural context. This process led to a 6% improvement in accuracy when it came to providing responses related to farming activities. Essentially, the fine-tuned model could now generate precise recommendations based on established agricultural standards and practices.
However, there is a trade-off that product managers and decision-makers need to consider. Fine-tuning is not a simple plug-and-play technique; it demands a substantial investment in both time and resources. It involves curating large and reliable datasets that accurately represent industry knowledge. Moreover, fine-tuning requires significant computational power to retrain the model effectively, which may not always be readily available depending on the scale of the project. Another consideration is the need for continuous updates. Industries are dynamic, and the knowledge base of even the most robust models will need regular updates to stay aligned with current practices, regulations, and new research findings.
Despite these challenges, fine-tuning remains a crucial step in transforming a general-purpose LLM into a specialized advisor capable of addressing intricate domain-specific questions with depth and relevance. By focusing on curating high-quality data and allocating the necessary resources, organizations can fine-tune models to become reliable assets in their sector.
Adding Dynamic Context with Retrieval-Augmented Generation (RAG)
While fine-tuning equips a model with essential domain-specific knowledge, there are plenty of situations where that alone isn’t enough. The reality is that industries are not static; they continuously evolve and require responses that reflect current events or fresh information. This is where Retrieval-Augmented Generation (RAG) becomes invaluable, as it enables the model to dynamically incorporate the most recent, relevant data from external sources.
The way RAG functions is by leveraging the foundational understanding gained from fine-tuning and enhancing it with updated information retrieved from external databases or knowledge repositories. Essentially, it’s a strategy that marries a model’s internal knowledge with real-time insights, allowing it to provide answers that are both accurate and current. Take the example of a farmer seeking guidance on when to plant seeds: while a fine-tuned model might offer general advice based on established agricultural practices, RAG enables that same model to consider the latest rainfall data or the current market prices for seeds. As a result, the recommendation becomes not only more precise but also more practically useful.
The impact of combining RAG with fine-tuning is significant. In trials conducted by Microsoft, applying RAG to a fine-tuned model resulted in an additional 5% increase in accuracy for industry-specific tasks. This layered approach, where fine-tuning builds a robust baseline of knowledge and RAG keeps that knowledge flexible and up-to-date, helps LLMs excel in real-world contexts that are constantly changing.
However, there’s a complexity to implementing RAG effectively. It requires maintaining a well-organized and regularly updated external database, which can be a logistical challenge. This database must be curated meticulously to ensure that the information remains accurate and relevant over time. Despite this, the payoff is substantial. The integration of RAG enables LLMs to transcend the limitations of their pre-trained data, offering the kind of dynamic and responsive intelligence that many industries, like agriculture, truly need.
In the broader scope, the advantage of RAG is its ability to provide a bridge between historical knowledge and present-day realities. This capacity to adjust and contextualize answers based on the most recent and relevant data enhances the value of LLMs in practical applications. For sectors that are influenced by fluctuating variables—be it weather in agriculture, financial markets, or evolving regulations in healthcare—RAG becomes a vital tool in ensuring that the insights generated remain timely and applicable.
Models on the Edge: Mistral’s Ministral Family and Lightweight AI Solutions
As the demand for edge-based AI solutions continues to grow, recent advancements in LLMs are reshaping what’s possible on smaller devices. A standout example is Mistral AI’s Ministral family, which includes the Ministral 3B and Ministral 8B models. These innovations are specifically crafted for edge applications, making them capable of running effectively on devices such as smartphones, laptops, and even some IoT setups. By focusing on delivering high-performance capabilities with a reduced parameter count, Mistral AI has made significant strides in pushing the boundaries of where and how these models can be deployed.
The Ministral 3B model is geared towards mobile scenarios, enabling advanced functionalities on smartphones or lightweight devices without consuming excessive resources. In contrast, the Ministral 8B is built for more robust environments, catering to devices with greater GPU capacity and computational power. This model is ideal for laptops or specialized hardware setups that demand higher performance while still maintaining efficiency.
One of the standout features of the Ministral family is its efficiency in handling contextual information while using a fraction of the parameters that traditional large-scale LLMs might require. Despite their smaller size, Ministral models have shown impressive results in key benchmarks, outperforming similar-sized offerings from major players like Google and Meta. They have demonstrated capabilities in areas such as multilingual support and common-sense reasoning, proving that being lightweight doesn’t mean compromising on depth or accuracy. For instance, in several multilingual and common-sense reasoning tests, Ministral’s models consistently delivered results that exceeded expectations, showcasing their strength in versatile, real-world applications.
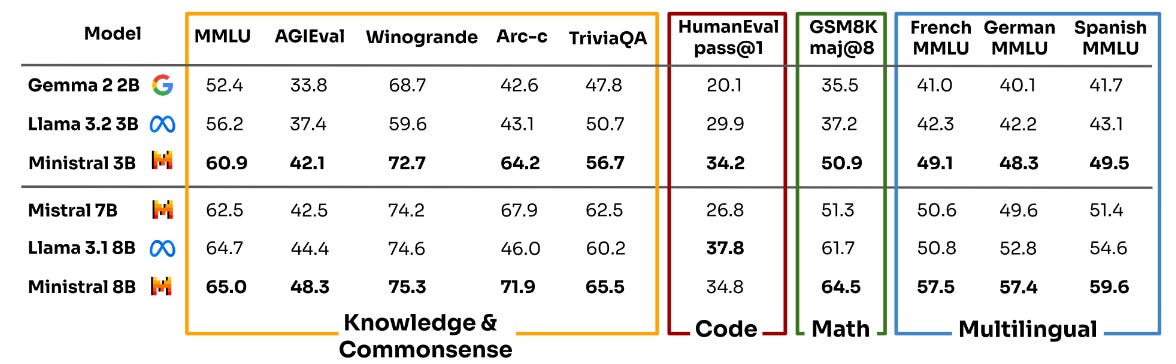
Image: Ministral 3B and 8B models compared to Gemma 2 2B, Llama 3.2 3B, Llama 3.1 8B and Mistral 7B on multiple categories (source: mistral.ai)
What’s particularly valuable about these lightweight models is their accessibility and practicality. For developers and organizations looking to deploy AI on consumer-grade hardware, the Ministral family offers an attractive alternative to relying solely on cloud-based solutions. By operating efficiently on edge devices, these models minimize the need for continuous cloud connectivity, which can lead to lower operational costs, reduced latency, and enhanced user privacy.
The ability of the Ministral family to perform effectively on edge devices isn’t just about convenience—it opens up a range of new possibilities for applications that demand real-time processing and autonomous functionality. From smart home systems that need to respond quickly to user commands, to agricultural devices that offer on-the-spot recommendations based on sensor data, lightweight models like Ministral enable AI to be embedded seamlessly into our everyday technology.
These advancements reflect a shift towards making AI more distributed and closer to the point of interaction, whether that’s a phone in a farmer’s hand or a laptop guiding critical decisions in a corporate office. It’s not merely a matter of shrinking the size of models; it’s about intelligently designing them to fit into a broader, decentralized AI ecosystem where they can respond and adapt in real time, directly at the edge.
Optimizing LLMs for the Edge: Techniques in Pruning, Distillation, and Quantization
Deploying large language models on edge devices introduces specific challenges due to the limited memory, power constraints, and the need for efficient processing speeds. This is where optimization techniques like pruning, distillation, and quantization become crucial.
Pruning serves to streamline the model by trimming away less critical or underutilized parameters, effectively reducing the overall size of the model. Think of it as a way to remove unnecessary branches from a tree while keeping its core structure intact. This method helps the model operate more efficiently on devices with constrained resources, ensuring that only the essential aspects remain to deliver robust performance.
Distillation, on the other hand, focuses on creating a more compact version of the original model. The approach involves training a smaller model—often referred to as a "student" model—to replicate the behavior and capabilities of the larger "teacher" model. By transferring the essential knowledge from the larger model, distillation allows the student model to perform nearly as well, but with a significantly smaller footprint. This makes it particularly advantageous for deploying AI on smartphones or IoT devices, where processing power and memory are more limited.
Quantization is all about reducing the precision of the model’s weights and computations. By converting 32-bit weights to lower-bit versions, quantization decreases memory usage and speeds up inference times without drastically affecting the model's accuracy. For applications like providing farmers with real-time advice in remote areas, where connectivity might be unreliable, quantized models can deliver fast, reliable insights without causing battery drain or excessive resource consumption.
Connecting the Dots: Personas in Agriculture and Data-Driven Decision-Making
In agriculture, the impact of LLMs extends beyond individual users, creating a ripple effect that influences an interconnected network of stakeholders. Each of these personas depends on accurate, timely information to make data-driven decisions:
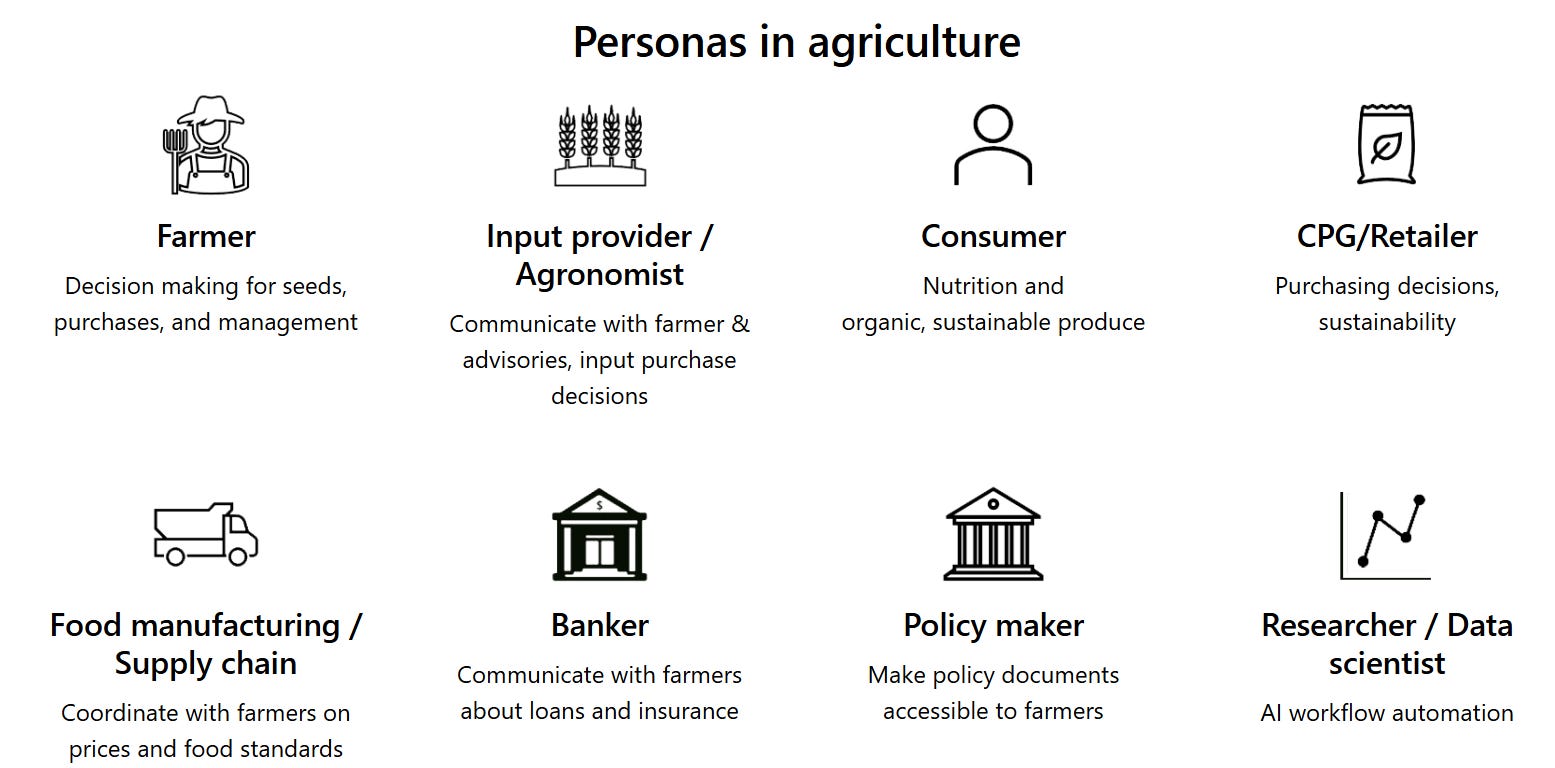
Image: Personas in Agriculture (source: microsoft.com)
Farmers, at the core, rely on precise insights to make key decisions about crop cycles, assess weather-related risks, and identify market opportunities. They’re the primary recipients of AI-driven advice that informs critical day-to-day choices in their fields.
Agronomists and Input Providers are the advisors, guiding farmers on selecting the best seeds, fertilizers, and pest control measures. Their role is to ensure that farmers are equipped with the right resources to maximize yield and maintain crop health.
Consumers, meanwhile, drive the demand for transparency and sustainability in agricultural products. They push producers towards delivering higher quality and accountability, influencing the types of data that LLMs must track and interpret.
Retailers and Consumer Packaged Goods (CPG) Companies aim to streamline supply chain operations while maintaining consistent quality standards. Their focus on efficiency and quality depends on accurate predictions and insights into production and logistics.
Bankers provide the financial backbone of the agricultural sector, assessing risks and extending financial support based on reliable data and projections. Their decisions are informed by a comprehensive understanding of market trends and risks, underpinned by data-driven analysis.
Policy Makers shape the agricultural framework by creating accessible policies, ensuring farmers comply with regulations, subsidies, and safety standards. Their decisions rely on a deep understanding of sector needs and impact.
Researchers / Data Scientists drive innovation in agriculture, developing AI models to automate workflows and deliver predictive insights. Their work informs strategic decisions, optimizing crop management and resource allocation.
The interconnected nature of these personas demonstrates how LLMs can serve as a powerful tool for enhancing decision-making and fostering collaboration throughout the entire agricultural ecosystem. By delivering precise and actionable insights to each stakeholder, LLMs enable a more cohesive and responsive approach to agricultural management.
Tailoring Edge Solutions for Farmers
For farmers working in remote regions, reliable connectivity can be a significant hurdle. They often can’t depend on cloud-based solutions due to inconsistent or non-existent internet access. This reality makes it essential to bring AI directly to their devices. By deploying fine-tuned and RAG-enhanced models on edge devices like smartphones, farmers can receive real-time, location-specific advice right where they need it. The use of distilled and quantized versions of these models ensures that these advanced AI systems run efficiently without overburdening the limited resources of the devices in use.
Integrating these edge models with localized document repositories enables the devices to function independently, allowing farmers to access crucial information even when they are disconnected from the internet. This autonomy is particularly valuable in rural areas where connectivity is a luxury rather than a given. Furthermore, pairing these edge models with on-device sensors creates a system capable of delivering hyper-local insights. The AI can take in real-time data related to soil conditions, climate factors, and crop status, and provide highly tailored recommendations, increasing the model’s relevance and practicality for on-the-ground decision-making.
Embracing Practical AI with Lightweight Models
The development of models like Mistral’s Ministral family signals an important shift toward more practical AI solutions designed specifically for edge computing. These models are compact, but still pack a punch in terms of functionality, making them a viable choice for a range of applications beyond agriculture, including smart home systems and autonomous technologies. Their design addresses the need for AI that can operate effectively without continuous cloud access, which not only saves bandwidth but also reduces latency and enhances data privacy.
For product managers, this shift calls for a strategic approach in selecting which models to deploy. The focus shouldn’t just be on choosing the most advanced model but on balancing the device’s capabilities with the need for up-to-date and context-aware information. Models like Ministral 3B and 8B offer real-world alternatives to traditional cloud-based setups, making them adaptable to various scenarios where reliability and efficiency are critical.
Insights for Domain-Focused Product Managers
Deploying large language models (LLMs) in specialized fields like agriculture requires a careful balance between cloud-hosted solutions and edge deployments. While cloud-based LLMs offer substantial capabilities and computational power, lightweight models designed for edge devices bring efficiency and real-time responsiveness. For product managers focusing on specific domains, this dual strategy introduces unique challenges that need to be managed effectively.
Key Considerations for Model Consistency and Performance
User Experience and Output Coherence: When using different LLMs for cloud and edge—such as a large model hosted on cloud infrastructure and a smaller edge model like Mistral’s Ministral series—it is crucial to ensure both models consistently deliver accurate insights. Differences in architecture or training data can lead to variations in output, which might confuse end-users who depend on coherent information across multiple devices.
Deployment Complexity: Managing a hybrid deployment strategy across cloud and edge devices involves handling different infrastructures, resource constraints, and maintenance protocols. Product managers need to establish a streamlined deployment strategy that reduces disruptions and keeps updates synchronized across platforms, maintaining compatibility and reliability.
Training and Fine-Tuning: Aligning training datasets and fine-tuning processes for each model is vital to ensure consistent interpretation and response to input data. Inconsistencies in training parameters or data sources could lead to diverging results, impacting critical decisions across the domain.
Balancing Cloud and Edge Models for Domain-Specific Needs
As more efficient models enter the market, finding the right balance between fine-tuning, deployment strategies, and real-time information retrieval becomes crucial. This balance ensures that AI delivers relevant and actionable insights to all key stakeholders—from analysts and engineers to advisors and policymakers. The objective is to build an ecosystem where every decision is backed by accurate, up-to-date information, empowering stakeholders to make informed choices and drive meaningful progress.
Ultimately, the challenge and opportunity lie in adopting these technologies thoughtfully. By focusing on deployment specifics and aligning model capabilities with real-world requirements, product managers can create a more resilient and responsive system, translating advancements in AI into improved decision-making and sustainable growth within their respective domains.
Disclaimer: The views and insights presented in this blog are derived from information sourced from various public domains on the internet and the author's research on the topic. They do not reflect any proprietary information associated with the company where the author is currently employed or has been employed in the past. The content is purely informative and intended for educational purposes, with no connection to confidential or sensitive company data.